
Stan AI na luty 2026
Programiści używający AI są o 19% wolniejsi, jednocześnie sami raportują, że są o 24% szybsi [1]. To nie błąd! Vibe coding[[1]] to po prostu nie jest to dobry pomysł. A powodów jest kilka.
Możliwości, kontekst i rozumienie
AI nie jest tak zdolne, jak wielu się wydaje i nie wiadomo czy będzie. Nie jest na takim poziomie rozwoju, aby było w stanie przejąć w całości pracę programistów i do tego zrobić to skutecznie. Jeśli już coś tworzy, to powstaje przy tym mnóstwo dziur, a za każdą iteracją tak naprawdę AI zaczyna od nowa, bo w istocie ono nic nie "rozumie" w takim sensie jak rozumie prawdziwa inteligencja.
Przykładem tego problemu jest coś, co zauważyłem w swoim vibe code'owanym projekcie, że aż złapałem się za głowę. Widać, że ta maszynka coś tam kombinuje, żeby osiągnąć cel, ale nie potrafi wpasować się w już istniejący kod. Zdaje się on bardziej AI przeszkadzać, niż być środowiskiem tworzenia.
To, co zrobiło AI w moim kodzie, to po prostu dokładało kolejne stany z użyciem useState [[2]] w React'cie — i tak powstało aż dziewięć osobnych useState, zamiast użyć jednego z obiektem. To jest antywzorzec, którego uczy się nawet juniorów, żeby go nie popełniali.
/* Każde przejście AI generowało extra logikę
* bez zrozumienia co się dzieje już w istniejącym kodzie
*/
const [locale, setLocale] = useState<Locale>('pl')
const [html, setHtml] = useState<string>('')
const [isRendering, setIsRendering] = useState(false)
const [copied, setCopied] = useState(false)
const [translationValues, setTranslationValues] = useState<
Record<string, string>
>({})
const [newVariableName, setNewVariableName] = useState('')
const [isAddingVariable, setIsAddingVariable] = useState(false)
const [variables, setVariables] = useState<string[]>([
'subject',
'previewText',
])
const [isSavingContent, setIsSavingContent] = useState(false)
Antywzorce wygenerowane przez AI Każdy stan osobno
interface TemplatePreviewPageState {
locale: Locale
html: string
translationValues: Record<string, string>
isCopied: boolean
isRendering: boolean
isSaving: boolean
}
//...pozostały kod
const [state, setState] = useState<TemplatePreviewPageState>({
html: '',
locale: 'pl',
isCopied: false,
isRendering: false,
isSaving: false,
translationValues: {},
})Przykładowy stan w jednym obiekcie
Przyczyn tych problemów jest kilka.
Pamięć
LLM[[3]] nie posiada pamięci. Każda sesja zaczyna się od nowa. Model nie pamięta, co napisał wczoraj, nie pamięta architektury, którą ustalono z nim tydzień temu ani nie pamięta konwencji użytych w projekcie. Istna tabula rasa. Jedyne, co taki model może zrobić, to za każdym nowym uruchomieniem odczytać wszystkie instrukcje, które mu udostępniono, wszystkie pliki konfiguracyjne, aż do momentu, do którego starczy mu fizycznie (na serwerze) dostępnej pamięci.
Dlatego model dodaje kolejne użycia useState, zamiast dostosować się do zastanego stanu kodu. Powiela kod, wbrew zasadzie DRY[[4]] i zamiast wyciągnąć go do osobnych plików jako niezależne i współdzielone funkcje, aż proszące się o zabezpieczenie ich testami jednostkowymi.
Halucynacje
Kolejnym istotnym problem są halucynacje. Wynika to z samego sposobu działania LLM, gdzie każde zapytanie wywołuje jakąś odpowiedź. Model w zasadzie nie ma opcji odpowiedzieć "nie wiem", bo halucynacje to świetny przykład feature, not a bug.[[5]] To bezpośrednia konsekwencja generatywnego charakteru modelu. Ten sam mechanizm, który pozwala modelowi tworzyć sensowne uogólnienia, umożliwia mu również tworzenie treści pozornie spójnych, lecz niezgodnych z rzeczywistością. Gdyby nie to, to w ogóle nie rozmawialibyśmy o generowaniu treści czy tym bardziej kodu.
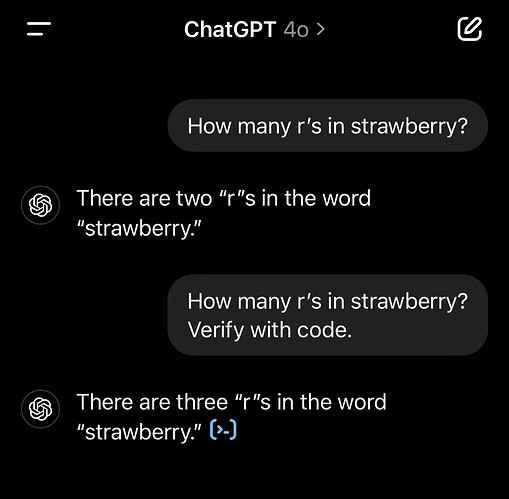
r występuje w słowie "strawberry" 🍓, to strzelał, że 2.Działa to mniej więcej tak — jeśli do systemu wpadną jakieś tokeny, to zostaną one przetworzone, a wynikiem tego procesu prawie zawsze będzie coś — bo prawie zawsze o coś się w danych treningowych "zahaczy".
Sytuacje, w których czat może odpowiedzieć nie wiem lub odmówić odpowiedzi jest niewiele. Może tak się zdarzyć w przypadku:
- konfliktu wewnętrznego,
- zbyt niskiej pewności poprawności odpowiedzi,
- wykrycia ryzyka halucynacji,
- tematu objętego restrykcją (prawa autorskie, bezpieczeństwo, prywatność)
Prawie zawsze będzie to jednak wynik działania zabezpieczenie w innej warstwie niż sam model. Jaskrawe przykłady takiego zachowania mogliśmy widzieć przy pierwszych wersjach ChataGPT, gdzie nie znajdywał nic w swoich danych treningowych lub warstwa bezpieczeństwa wykrywała błąd po stronie samego modelu:
As an AI language model with a limited knowledge cutoff, I’m unable to provide details about [SUBJECT].
Rozumowanie wielokrokowe i planowanie
Obecna architektura modeli sztucznej inteligencji generuje tekst token po tokenie — każdy kolejny token jest statystycznie najbardziej prawdopodobną kontynuacją. Przy nietrywialnych zadaniach programistycznych często wymagane jest zaplanowanie kilka kroków naprzód ze względu na powiązania i zależności kodu w ramach całego projektu. Kod niestety nie żyje w próżni i nie jest zwykłą wiadomością wysyłaną w czacie.
Programista jest w stanie zauważyć ten łańcuch zależności i zaplanować kolejność. AI podchodzi do każdego kroku niezależnie — generuje rozwiązanie dla tego, co ma bezpośrednio przed sobą, nie mając "mentalnej mapy" całego planu, bo też nie ma takiej zdolności.
Plasterkiem na to jest chain-of-thought prompting[[6]] — kiedy model "myśli na głos", symulując planowanie przez generowanie tekstu o planowaniu. Niestety nie jest to faktyczne planowanie w jakiejś wewnętrznej reprezentacji.
Spójność architektoniczna
To jest jedna z większych bolączek programistów i to o czym wspomniałem w przykładzie. AI nie jest w stanie przestrzegać zasad architektury i przyjętych w projekcie konwencji, gdyż ich zwyczajnie nie rozumie. Nie zachodzi w nim żaden proces przypominający ludzkie rozumowanie.
To jest właśnie to, co się stało w przykładzie wielokrotnego użycia useState — model nie łamie żadnej reguły składni JavaScript'a, TypeScript'a ani React'a. Kod działa, jednak łamie konwencje, które istnieją z konkretnego powodu, i tego powodu model nie jest w stanie pojąć, bo to wymaga rozumienia dlaczego, a nie tylko wiedzy co, po czym i kiedy następuje.
Dokładnie z tego też powodu vibe code'owana aplikacja nie nadaje się na dłuższą metę do użycia, która w zamierzeniu ma działać lata i w tym czasie być rozwijana, naprawiana i utrzymywana
Rzadkie technologie = słabe wyniki
Kolejnym czynnikiem, o którym trzeba wspomnieć, to produktywność AI spada drastycznie wraz z rozmiarem projektu i rzadkością technologii. AI ma dużo danych treningowych — im popularniejsza technologia, tym większy jej udział w tych danych.
React z popularnymi bibliotekami? Świetnie, mamy tego dużo! Języki takie jak Lua, Rust, OCaml pojawiają się znacznie rzadziej w danych treningowych. Można temu zaradzić, dając AI dokumentację, ale znowu — to tylko plasterek na większy problem.
Słaby kod, lecz kod
Załóżmy, że udało się doprowadzić do utworzenia aplikacji z użyciem AI, która działa tak, jakbyśmy tego oczekiwali. Co dalej? Kodowanie tylko z użyciem AI, jest obarczone ogromnym ryzykiem, gdyż samo wygenerowanie kodu — nawet dobrego — nie wystarczy.
Co chwilę słychać o przypadkach, gdzie ktoś wystartował z fantastyczną aplikacją wygenerowaną przez LLM. Zrobił to bardzo szybko i bez doświadczenia, reklamując to na Twitterze jako swoje success story i zbierając przy tym masę lajków. Rzeczywistość szybko weryfikuje takie przypadki. Okazuje się często, że aplikacja nie miała żadnych zabezpieczeń, a wszystkie jej klucze dostępowe oraz dane klientów już hulają po internecie, bo nie były należycie zabezpieczone. Kilka przykładów:
- Tea App (lipiec 2025) - Wyciek 72 000 zdjęć, w tym 13 000 zdjęć dowodów osobistych z weryfikacji użytkowników. Powodem było pozostawienie bazy danych Firebase z domyślnymi ustawieniami — bez zabezpieczeń. [2]
- EnrichLead (marzec 2025) — SaaS zbudowany w 100% przez Cursor, zero ręcznie pisanego kodu. Dwa dni po wiralowym poście chwalącym się tym faktem: "guys, I'm under attack". API keys we frontendzie, brak autentykacji, otwarta baza danych. Autor: "as you know, I'm not technical". Tydzień później aplikacja zostaje zamknięta[3].
- Moltbook (styczeń 2026) — najświeższy przypadek — Platforma dla agentów AI. 3 dni po premierze wyciekło 1,5 miliona kluczy API, 150 000 tokenów API oraz adresy email[4].
Inne problemy z twórczością AI:
- 45% kodu generowanego przez AI zawiera luki bezpieczeństwa.[5]
- 1 na 5 CISO zgłosił poważny incydent spowodowany kodem AI.[6]
- OpenAI klucze API — wzrost wycieków r/r w 2023 o 12 razy.[7]
W tych przypadkach AI wygenerowało działający kod, a jakże! Jednak nie było nikogo w tym procesie, aby pomyślał o bezpieczeństwie lub był w stanie je zaimplementować. Jasno z tego wynika, że aplikacje i oprogramowanie jak produkt to coś więcej niż tylko działający kod.
Mityczna produktywność
Jak widać, na dzień dzisiejszy LLM-y nie są w stanie generować gotowych rozwiązań od początku do końca, ani tym bardziej zastąpić programistów. Pozostaje im zatem rola kolejnego narzędzia. Czy jednak realnie przyspiesza ono pracę? Najnowsze dane sugerują, że wpadliśmy w pułapkę subiektywnego poczucia produktywności.
Badanie przeprowadzone na grupie doświadczonych programistów open-source[[7]] pokazuje szokujący paradoks: deweloperzy używający AI byli obiektywnie o 19% wolniejsi w rozwiązywaniu złożonych problemów niż ci, pracujący bez wsparcia modeli. Co zaskakujące, badani ulegli wrażeniu, że są o 24% bardziej wydajni. Nawet po zakończeniu zadań utrzymywali, że ich produktywność jest o 20% większa [1]. To może sugerować, że szybkość generowania kodu przez AI (literki pojawiające się na ekranie jak literki w Matrixie) mylimy z szybkością rozwiązywania problemu.
Wyniki te korelują z obszernym studium badaczy ze Stanfordu [8]. Potwierdza ono, że wpływ AI na pracę jest silnie uzależniony od kontekstu. Największe zyski (rzędu 30-40%) odnotowano w zadaniach o niskiej złożoności oraz w projektach typu greenfield[[8]], gdzie kod powstaje „od zera”. Sytuacja zmienia się drastycznie w projektach typu brownfield[[9]]. Tam, ze względu na konieczność analizy istniejących zależności, zysk z AI drastycznie spada, a w przypadku wysokiej złożoności zadań, prawdopodobieństwo, że AI wręcz utrudni pracę i wprowadzi konieczność czasochłonnych poprawek i refactor'ów[[10]], staje się bardzo wysokie.
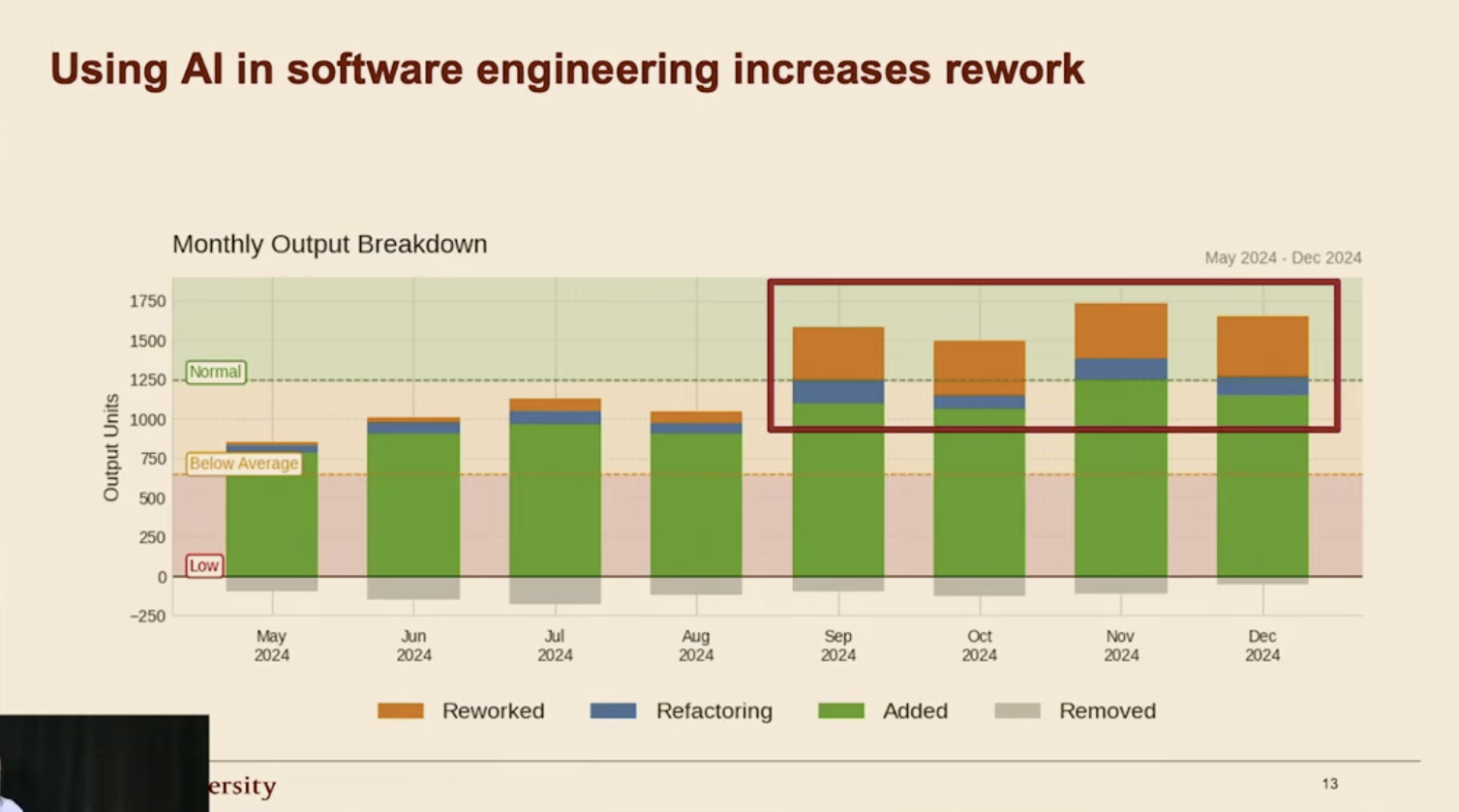
Tyle doświadczenie deweloperzy, a co z juniorami? Anthropic opublikował w styczniu 2026 badanie [9], które odpowiada na to pytanie. W randomizowanym eksperymencie na 52 programistach (głównie juniorach) uczących się nowej biblioteki Python:
- Grupa używająca AI uzyskała 17% niższy wynik na teście
- Przyspieszenie w samym zadaniu było nieistotne statystycznie
Uczestnicy spędzali do 30% czasu na przygotowaniu zapytań do AI. Tak uzyskany kod dość bezmyślnie wklejali do swojego programu.
Muszę tu zrobić pauzę, bo szczerze mówiąc, to bezmyślne wklejanie kodu wygenerowanego przez AI nie różni się niczym od tego, jak przed erą LLM-ów używano StackOverflow. W razie problemów z kodem było to pierwsze miejsce, do którego programiści lecieli po pomoc (bo tak im mówiło Google) i kopiowali rozwiązania na chybił trafił. Czasem biorąc kod z – o zgrozo – opisu problemu (czyli błędny), zamiast z najwyżej ocenianej odpowiedzi.
Różnica zdaje się polegać na skali i barierze wejścia. SO wymagał podstawowych umiejętności szukania. Bo selekcji — jak już wspomniałem — to już niekoniecznie. AI dostarcza rozwiązanie bezpośrednio do edytora kodu, eliminując resztki wysiłku. Zarówno poznawczego, jak i klikania w kąkuter. Zaczynam podejrzewać, że problemem nie są tylko LLM, ale skłonności ludzi do minimalizowania wysiłku włożonego w pracę, żeby nie powiedzieć lenistwa.
Podejście ma znaczenie
Badanie Anthropic zidentyfikowało również wzorce zachowań użytkowników, które pomagają w nauce, jak i takie, które jej wręcz zapobiegają.
Słabe wyniki (<40% na teście) otrzymali programiści z takim podejściem:
- AI delegation — pełne oddelegowanie, najszybciej ukończone, ale nic nie zapamiętane
- Progressive AI reliance — zaczęli sami, potem oddelegowali wszystko AI
- Iterative AI debugging — używali AI do debugowania zamiast zrozumienia problemu
Wzorce prowadzące do dobrych wyników (>65% na teście):
- Generation-then-comprehension — generowali kod, potem pytali "dlaczego to działa?"
- Hybrid code-explanation — prosili o kod oraz wyjaśnienie na raz
- Conceptual inquiry — pytali o koncepcje, kodowali sami (najszybsze podejście do uczenia się)
Pięknie podsumowuje to jedno zdanie z badania:
Wysiłek poznawczy — i nawet bolesne utknięcie — jest prawdopodobnie ważne dla budowania biegłości [w przedmiocie nauki].
Dlaczego tak się dzieje?
Mamy ponad 70 lat badań nad jakością zarządzania, które pokazują, że eliminowanie źródeł błędów jest znacznie efektywniejsze niż naprawianie błędów w trakcie procesu. Nie warto przyspieszać procesu kodowania, jeśli spowalnia to proces debugowania. Można zmarnować znacznie więcej czasu na debugowanie złego kodu niż na przezwyciężenie blokady przy pisaniu.
Brian Kernighan napisał w The Elements of Programming Style:
Dobrze wiemy, że debugowanie jest dwa razy trudniejsze niż pisanie programu. Jeśli zatem piszesz najlepszy kod jaki potrafisz, to jak w ogóle będziesz go debugować?
I jest to dokładnie to, co wykazało badanie Anthropic. Junior z protezą w postaci AI nie jest w stanie zdebugować tak wyprodukowanego kodu.
Co działa?
Wyobraź sobie, że musisz poświęcić pół dnia na konfigurację, zanim linter zacznie działać. Brzmi jak szaleństwo, a tymczasem to standardowy sposób pracy z AI. Nikt nie wymyślił jeszcze, jak efektywnie je wykorzystywać do pisania kodu, bo wątpię, że odpowiedzią jest automatyczne generowanie całych programów. [10]
AI w dzisiejszej postaci ma pewne obszary, w których rzeczywiście potrafi być skuteczne — tam, gdzie kontekst jest statyczny i ograniczony.
Tworzenie dokumentacji
Dokumentacja od zawsze jest problematyczne. Jednym z powodów jest, to, że kod prawie nigdy nie jest skończonym dziełem, tylko żyjącym utworem, zmieniającym się w czasie. Dokumentacja musiałaby za nim nadążać albo generować się automatycznie.
Drugi problem wynika z pierwszego — deweloperów może skutecznie zniechęcać syzyfowość tej pracy. Nie do pominięcia jest też fakt, że nie muszą być jednocześnie dobrzy w pisanie kodu i utworów języka naturalnego. Jeśli wypracowania w szkole nie była ich bajka, to pisanie za każdą zmianą małej pracy licencjackiej może być skrajnie nieatrakcyjne. Co więcej, dobra dokumentacja może zabrać więcej czasu niż samo pisaniem kodu (w ramach tego samego zadania, kod + dokument). Stąd się biorą takie kwiatki jak
"dobry kod komentuje się sam"
Problem z tym zdaniem jest taki, że kod komentuje się sam tylko dla ludzi, którzy dogłębnie taki kod rozumieją, a i to nie zawsze. Fakt, że na pierwszy rzut oka rozumiem linijkę, na którą akurat patrzę, nie znaczy, że rozumiem jej konsekwencję trzy pliki dalej i wpływ na każdy scenariusz w realizowanym procesie biznesowym.
W takich narzędziach jak Claude Code, można dodać komendy i jedną z nich może być /docs, po której agent sprawdza, co jest w dokumentacji, a co aktualnie jest w kodzie. Wywołanie takiej komendy można skonfigurować jako pre-commit hook[[11]], czyli uruchamiane przed zatwierdzeniem zmian w projekcie. W efekcie to uniemożliwi dodanie zmian do projektu bez dokumentacji.
Code Review[[12]]
Jak już ustaliliśmy, ludzie są leniwi. A zdolni ludzie są leniwi do kwadratu. "Zdolny ale leniwy" nie wzięło się znikąd. Ciężko pracujemy na tę reputację.
Statyczna analiza kodu dla programistów jest najmniej ulubionym zajęciem zaraz po spotkaniach i wsparciu technicznym. Nic dziwnego, że robią to najniższym możliwym kosztem.
W wyniku tego widzimy takie zjawiska jak jeden komentarz pod zmianą 2000 linii kodu "LGTM" (dla mnie spoko) i zatwierdzenie zmian bez szczególnego wgłębiania się w ich treść czy sens. Zdarza się, że ktoś rzeczywiście zacznie przeglądać kod i wyłapie parę rzeczy. Jednak często będzie to miało związek z jego ulubionym stylem i manierą pisania.
Porządna kontrola jakości na tym etapie wymaga dużo czasu i energii. Tak naprawdę tyle, co zwykłe zadanie a jest traktowane jak coś, co się robi z doskoku. Trzeba przeanalizować kontekst biznesowy, przeczytać opis zadania i zrozumieć, jaki jest oczekiwany rezultat. Takiej jakości review, jest bardzo rzadkie.
Narzędzia AI do sprawdzenia kodu nie mają takich ograniczeń i problemów — zrobione według zadanych instrukcji potrafią być o wiele bardziej szczegółowe. Często zaglądając tam, gdzie programista nie zwróciłby uwagi.
Co ważne, maszyna się nie męczy i nie będzie znudzona tym, że po raz piąty tego samego dnia musi sprawdzić zmiany w kodzie. Uruchamia się, sprawdza i pisze nowe komentarz. Reszta jest kwestią dostosowania konfiguracji.
Muszę tutaj zaznaczyć, że w żadnym razie nie twierdzę, że jest to panaceum na wszystkie bolączki tego procesu ani, że można wyeliminować z niego człowieka całkowicie, zwłaszcza że jestem zwolennikiem podejścia human-in-the-loop[[13]] Jest to po prostu dodatkowy etap weryfikacji wprowadzanych zmian. Przy mocno zaangażowanych deweloperach można zauważyć, że poprawiają błędne wnioski i twierdzenia AI, jeśli wprowadzone przez nich zmiany są celowe i wykorzystują mechanizmy, na które automat nie zwrócił uwagi. A bywa i tak.
Informacja zwrotna i co dalej?
W tym samym procesie można dołożyć jeszcze jedną cegiełkę — komendę ze sprawdzeniem komentarzy i uwag kodu. Zarówno od prawdziwej, jak i sztucznej inteligencji. Następnie podsumowanie i ocena istotności uwag, a na koniec ich wdrożenie. Z racji tego, że działamy w ograniczonym kontekście, to LLM bardzo dobrze sobie tutaj radzi.
Treści
Kolejne zastosowanie to wszelkiego rodzaju treści wyświetlane użytkownikowi w aplikacji. Potrzebujesz czegoś na szybko do prototypu? AI da radę. Maile marketingowe, powitalne, listy oczekujących, subskrypcyjne — tutaj rozwiązanie mamy od ręki. Łatwość i trafność w generowaniu tego typu treści wynika z tego, że marketing funkcjonuje w dużej mierze w przestrzeni publicznej i niechybnie znalazł się w konkretnej ilości w danych treningowych LLM.
Poza tekstami, które będą służyć użytkownikom, możemy również zautomatyzować tworzenia opisów PR. Moment ich tworzenia jest często momentem, kiedy nie ma się już głowy do tworzenia wymyślnego opisu o poczynionych zmianach. "Po co opis, przecież to jasne — właśnie od tego jest ten kod". Strasznie to blisko do samo dokumentującego się kodu, prawda? Zadanie stworzenia obszernego i ładnie ustrukturyzowanego opisu można spokojnie oddelegować maszynie — to tylko opis, który przeczytają ludzie. Jedyne ryzyko to to, że opis będzie brzmiał sztucznie, może być nadmiernie pedantyczny i będzie zawierał niezdrową liczbę emoji.
PRD[[14]] i analiza biznesowa
Jeszcze jednym z wartościowych zastosowań AI to analiza biznesowa na weryfikację swoich pomysłów i osadzenie ich w rzeczywistości. Kiedy mamy pomysł, bardzo szybko pierwsza weryfikacja może nastąpić właśnie przez LLM. Te maszynki są dobre do utworzenia pierwszego szkicu tego, co powinno być w aplikacji i jakie funkcjonalności trzeba uwzględnić. Taki dokument to dobry punkt początkowy — od niego można zacząć rozbudowę opisu, założeń i wymagań. Następnie można go wykorzystać do kolejnych iteracji i burzy mózgów w czacie.
Kiedy mamy już taki dokument, to na jego podstawie możemy zlecić automatowi utworzenie PRD — Product Requirements Document po prostu jako prompt[[16]]. A od tego już tylko krok od user stories[[15]] i konkretnych zadań na urzeczywistnienie pomysłu jako aplikacji.
I znowu — jeśli to jest zupełnie nowy twór w popularnej technologii, to agent AI poradzi sobie z wdrożeniem przynajmniej prototypu takiego dokumentu.
Podsumowanie
LLM-y nie nadają się do pisania dobrych, bezpiecznych i rozwijalnych aplikacji bez nadzoru. Słowem — wszędzie tam, gdzie kontekst jest ograniczony, a zadanie dobrze zdefiniowane. Tam, gdzie trzeba rozumieć i rozwijać istniejący kod. Do działania w szeroki kontekście zwyczajnie braknie pamięci, o rozumieniu nie wspominając. LLM może i nie policzy liter w truskawce, ale z pewnością wygeneruje system płatności. Co może pójść nie tak?
Umówmy się — liczba linii kodu/commit'ów[[17]] na dzień nie jest dobrym miernikiem produktywności. Niestety niektórzy z was jeszcze nie są gotowi na tę rozmowę.
Przypisy
- Becker, J., Rush, N., Barnes, E., & Rein, D. (2025). Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity. arXiv:2507.09089. https://metr.org/blog/2025-07-10-early-2025-ai-experienced-os-dev-study/
- Tea App data breach (lipiec 2025). Netlas Security Research. https://netlas.io/blog/vibe-coding-security-risks/
- @leojrr. (2025, marzec). EnrichLead incident thread. X/Twitter. https://x.com/leojrr/status/1900767509621674109
- Moltbook exposes user data and API keys. (2026, styczeń). Infosecurity Magazine. https://www.infosecurity-magazine.com/news/moltbook-exposes-user-data-api/
- Veracode. 2025 GenAI Code Security Report. https://www.veracode.com/resources/analyst-reports/2025-genai-code-security-report/
- Aikido Security. State of AI in Security & Development 2026. https://www.aikido.dev/state-of-ai-security-development-2026
- GitGuardian. (2024). State of Secrets Sprawl 2024. https://www.bleepingcomputer.com/news/security/over-12-million-auth-secrets-and-keys-leaked-on-github-in-2023/
- Evil Martians. (2025). Does AI Actually Boost Developer Productivity? https://www.youtube.com/watch?v=tbDDYKRFjhk
- Shen, J. H. & Tamkin, A. (2026). How AI Impacts Skill Formation. arXiv:2601.20245. https://www.anthropic.com/research/AI-assistance-coding-skills
- r/ExperiencedDevs. Study discussion: Experienced devs think they are 24% faster with AI, but are actually 19% slower. Reddit. https://www.reddit.com/r/ExperiencedDevs/comments/1lwk503/study_experienced_devs_think_they_are_24_faster/
[[1]]: vibe coding (en. "kodowanie na czuja") — tworzenie kodu przez AI na podstawie ogólnych poleceń, weryfikując jedynie wygląd i działanie aplikacji z pominięciem aspektów jakościowych kodu. Termin spopularyzowany przez Andreja Karpathy'ego.
[[2]]: useState — hook w React do utrzymywania w pamięci stanu wyświetlanych wartości lub komponentów w aplikacji.
[[3]]: LLM - Large Language Model — (en. duży model językowy) model sztucznej inteligencji trenowany na ogromnych zbiorach tekstu, zdolny do generowania i przetwarzania języka naturalnego.
[[4]]: DRY - Don't Repeat Yourself - (en. Nie powtarzaj się) — zasada programowania mówiąca, że każda część logiki powinna istnieć w kodzie tylko raz. Powtórzenia prowadzą do błędów i utrudniają utrzymanie kodu.
[[5]]: feature, not a bug (pol. "to funkcja, nie błąd") — ironiczne określenie sytuacji, gdy pozorne ograniczenie systemu jest w rzeczywistości zamierzonym elementem jego działania.
[[6]]: chain-of-thought prompting (en. "podpowiadanie łańcuchem myśli") — technika promptowania LLM, gdzie model jest instruowany, by "myślał krok po kroku", co poprawia wyniki w zadaniach wymagających rozumowania.
[[7]]: open-source (en. "otwarte źródło") — oprogramowanie z publicznie dostępnym kodem źródłowym, który można przeglądać, modyfikować i rozpowszechniać.
[[8]]: greenfield (en. "zielone pole") — projekt tworzony od zera, bez istniejącego kodu ani ograniczeń technicznych.
[[9]]: brownfield (en. "pole z zabudową") — projekt rozwijany w ramach istniejącego systemu, z legacy kodem i zależnościami.
[[10]]: refactor (en. "refaktoryzacja") — restrukturyzacja istniejącego kodu bez zmiany jego zewnętrznego zachowania, w celu poprawy czytelności, wydajności lub architektury.
[[11]]: pre-commit hook — skrypt uruchamiany automatycznie przed zatwierdzeniem zmian w systemie kontroli wersji (np. Git). Może blokować commit[[17]], jeśli kod nie spełnia określonych warunków.
[[12]]: code review (en. "przegląd kodu") — proces weryfikacji kodu przez innego programistę przed włączeniem zmian do głównej gałęzi projektu.
[[13]]: human-in-the-loop (en. "człowiek w pętli") — podejście, w którym człowiek uczestniczy w procesie decyzyjnym systemu automatycznego, weryfikując lub korygując jego działania.
[[14]]: Product Requirements Document (PRD) — dokument wymagań produktu. Specyfikacja opisująca cele, funkcjonalności i ograniczenia planowanego produktu.
[[15]]: User stories (en. "historyjki użytkownika") — krótkie opisy funkcjonalności z perspektywy użytkownika końcowego, w formacie "Jako [rola] chcę [cel], aby [korzyść]".
[[16]]: prompt (en. "polecenie", "zapytanie") — tekst wejściowy przekazywany do modelu językowego, zawierający instrukcje, kontekst lub pytanie. Jakość promptu bezpośrednio wpływa na jakość odpowiedzi LLM.
[[17]]: commit (en. "zatwierdzenie") — w systemie kontroli wersji Git: zapisanie zmian w repozytorium wraz z opisem i unikalnym identyfikatorem. Tworzy punkt w historii projektu, do którego można wrócić. Niemalże odpowiednik zapisu stanu gry.



